Introducing Datastore Classic
Background
The aim of the IATI Datastore is to help users quickly access the chunks of IATI data they need, without having to download everything from the IATI Registry. For example: a user in Liberia may only want to download activities tagged with the recipient country Liberia, without having to download every other activity.
The first IATI Datastore (“v1 Datastore”) was built in 2013/2014 by the Open Knowledge Foundation. It worked well, but always remained in “alpha” status and work to improve it stopped in mid 2015. Over time, it gradually became out of date, with an increasing backlog of bugs and feature requests. We wanted to see if it was possible to get it up and running again. As the IATI Secretariat releases all its software as open-source code (which is great!), we were able to take the original code and further develop it.
For some of our own purposes (supporting country-level systems), we need:
- as much data as possible (including data which doesn’t validate against the schema);
- the latest data (preferably within 24 hours of publication);
- unchanged, original XML (we need to be confident this is the original donor statement of their activities);
- large extracts of XML data (e.g. all data for one reporting organisation for one country);
- reliable service and flexibility to quickly debug and fix issues as they arise;
- ability to add small new features as needed.
Note that a number of these requirements are needed not only for country level systems but are more generally useful.
Some of these requirements could be met by using the new IATI Datastore (“v2 Datastore”) or by requesting further improvements to it. However, such requests would have to be balanced against other users’ needs and the capacity to implement other changes. We wanted to consider the alternative of making the v1 Datastore available in parallel, if we could get it up and running again.
Introducing Datastore Classic
We found that the v1 Datastore code was clear and well organised, with a robust test suite. It needed some work to bring it up to date, particularly to upgrade the code from Python v2 to Python v3 (Python v2 is no longer supported as of January 1st, 2020), as well as to update dependencies, some of which dated to 2012 (e.g.). Over a period of a couple of weeks, we brought the code up to date, fixed bugs, and added a small number of new features (see below, list of bug fixes and new features).
To reflect these improvements, we decided to rename our fork of the original code Datastore Classic.
Outcomes
As a result of these improvements, we’re closer to having a robust piece of software:
- it runs on a €15/month server;
- the initial import takes around 16 hours; nightly updates take around 1 hour;
- it’s easy for users to see whether Datastore Classic is facing any issues;
- it has a simple and clear pipeline and codebase, making it easy to identify bugs and make improvements;
- the software is fully up to date, using the latest dependencies, and an extensive set of tests are passing;
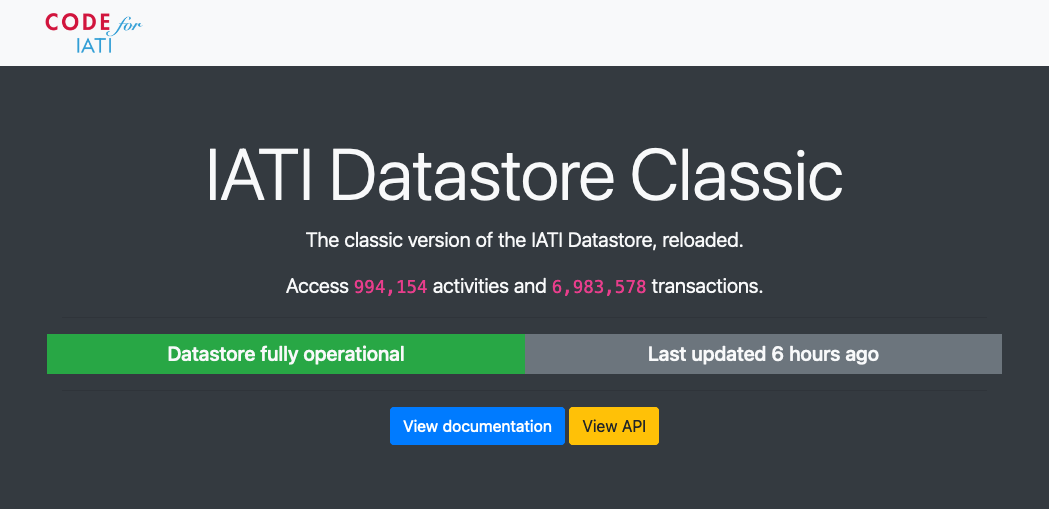
- 994k activities are accessible in Datastore Classic, compared with 903k in the v2 Datastore (NB, these numbers are not directly comparable, because v2 Datastore excludes v1.x IATI activities and activities that don’t validate against the schema).
It’s also useful to have a piece of software that we are able to flexibly adapt as our needs change, via a versioned API. For systems currently using the v1 Datastore, this provides an additional option for systems to transition at their own pace (essential for donor- or government-funded projects with long lead times).
Nevertheless, there are some challenges, and a number of things that could be improved. It currently runs fine on a €15/month server, but might struggle to handle a lot of concurrent requests. CSV download is particularly slow, and a couple of filters take a while to respond. We are looking into this (and welcome pull requests!).
What’s next?
Datastore Classic is up and running for anyone who would like to use it. Meanwhile, we are continuing to work our way through some remaining issues. Having this software working now provides us with options and allows us (and others!) to make an informed decision about which back-end we would like to use to power country-level systems. It also provides a potential option for other software providers to host their own instance to support their own tools. We would be very happy to discuss with other individuals or organisations that would be interested in using, maintaining, further developing or forking this software!
Once we’ve tested a little more, we would like to make clear commitments around how long we will keep the public instance running, with uptime targets and targets for resolving major issues. We will also provide a versioned API that ensures API requests today return the same structure of data in future. We would also like to consider other feature improvements – let us know!
List of bug fixes and new features
- Upgraded to Python3 (#93)
- Switched to HTTPS (all requests get upgraded)
- Provided prettier documentation (#97)
- Added a home page, including the query builder, information about health status, and information when data is still being loaded (#133)
- Added a status API page that provides an accurate indication of the status (#101)
- Properly implemented CORS (#100)
- Added search on titles and descriptions (#168)
- Recipient region, country and sector also search transactions by default now (#117)
- Cleaned up git branches
- Added further tests, and we now have an accurate reflection of test coverage (90%)
- Updated codelists (#95)
- Fixed a bug with hierarchies (#114)
- Fixed a bug for searching on recipient-region.text
- Upgraded database to use Postgres 13
- Switched to using iatikit to download data much faster and more reliably (#131)
- Compare existing hash of data with new data, in order to massively speed up import (#157)